
Anano 楼主
Anthropic 拒绝公开Mythos的模型架构,但一项异常的测试成绩引发了社区猜测。
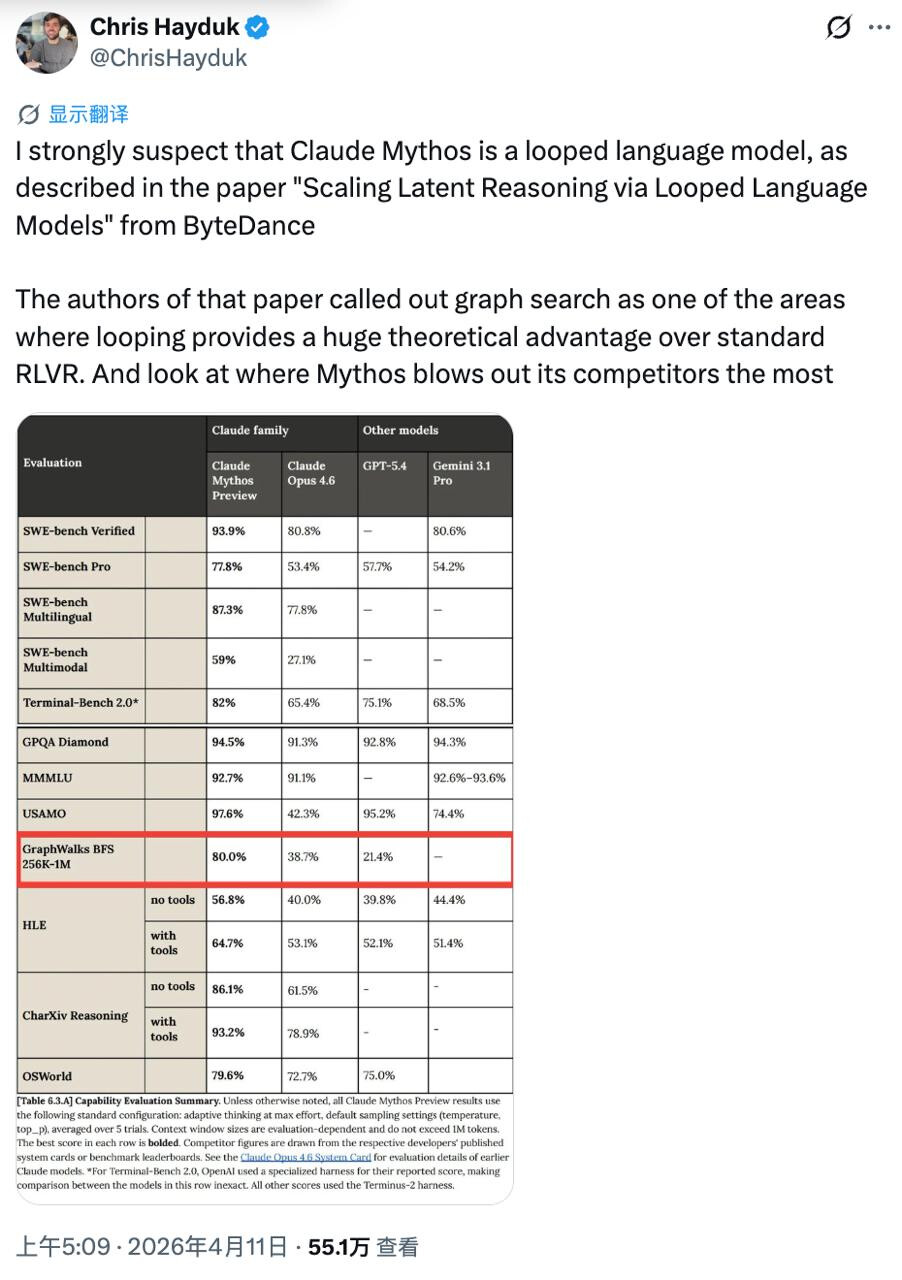
Anthropic官方 system card 显示,Mythos 在 GraphWalks BFS 测试(让模型在复杂图结构中做广度优先搜索)中得分 80.0%,Opus 4.6 为 38.7%,GPT-5.4 仅 21.4%。其他基准上各家差距远没有这么大。
Meta机器学习工程师 Chris Hayduk 最先指出,这个异常尖峰恰好指向一种特定架构:循环语言模型。
字节跳动 Seed 团队去年 10 月发表论文提出 LoopLM,核心思路是让同一组 Transformer 层对输入反复跑多遍,在模型内部完成推理,而不是像现在的思维链那样靠生成大量文字来「思考」。
图灵奖得主 Yoshua Bengio 为论文共同作者。论文明确指出,图搜索正是这种架构的理论强项。论文开源的小模型 Ouro 中,14 亿参数版本就能打平约 40 亿参数的标准模型。
第二条线索:Mythos 在 SWE-bench 上消耗的 token 量只有 Opus 4.6 的 1/5,但推理速度反而更慢。
普通模型输出越少就越快,但如果计算藏在模型内部的反复迭代里,这个矛盾就说得通了。
Anthropic 将架构列为「研究敏感信息」,未作任何回应。
这一切仍是推测,但如果属实,意味着下一代顶级模型的架构突破可能部分源自中国团队的公开研究。
论文中的相关定理:

TOPIC OWNER










